Vector processor Units (VPUs) are well-known accelerators due to their capability to exploit data-level parallelism with single-instruction multiple-data. VPUs have applicability in various application domains such as machine learning, scientific simulations, etc. The gains in performance from a VPU are realized majorly through a deeply pipelined data path, predicated execution, multiple lanes of execution and features such as chaining. The capabilities and applicability of a VPU are greatly extended in the MEEP project with a suitable memory path and a data path to support vector operations with sparse and very long vector operands, considering the requirements of various practical vector operations.
The MEEP VPU supports RISC-V vector instructions v0.7.1, and is equipped to work in two modes of operations: ACME-classic-mode, and ACME- mode. ACME-classic-mode is applicable when the operand vectors are short dense vectors. To exploit the available spatial and temporal localities in these scenarios, the vector loads and stores are carried out through the traditional cache hierarchy. The limit for operand vector length in this mode is determined by the vector register space on the VPU. The MEEP VPU operates in ACME-mode for operand vectors longer than this limit. The ACME-mode is also applicable for short, and long sparse vectors and is effective when the operand vectors do not achieve significant performance gains due to the normal cache hierarchy (i.e. streaming, non-unit stride or sparse memory accesses).
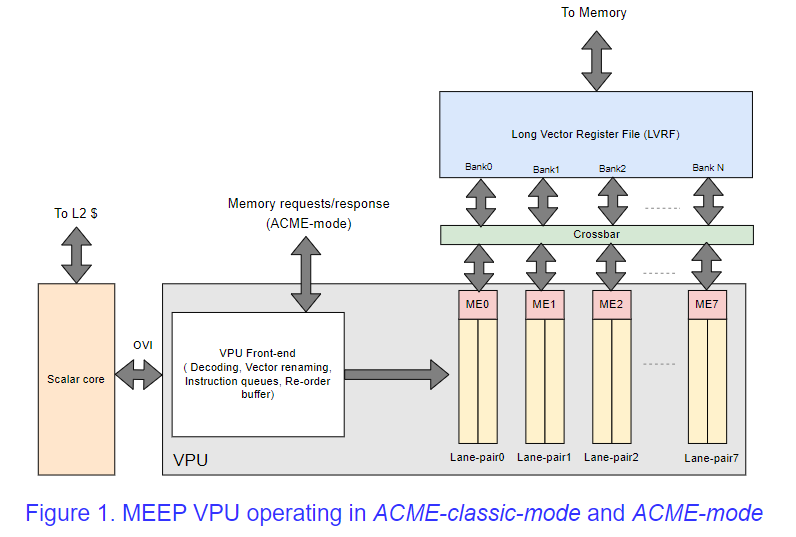
The memory path of ACME-mode, which bypasses the cache memory (L1 and L2 data caches), includes an entity close to memory, which upon a request from the VPU, writes or reads the requested elements to a private memory close to the VPU. This memory is termed a Long Vector Register File (LVRF), which maintains vector registers as per the RISC-V vector extension ISA. The LVRF is much larger than the Vector Register File (VRF) on the VPU, and is used as the vector register bank in the ACME-mode. The movement of data between the LVRF and VPU is managed by DMA engines called Micro-Engines (MEs). A high-level view of the MEEP VPU is depicted in Figure 1, in which all the modules involved in the execution of the ACME-classic and ACME modes are represented. MEs are configured at the beginning of any instruction in ACME-mode, and MEs read from or write to LVRF based on the number of valid sources. For example, the read DMA of ME reads a segment of the operand vector data from LVRF every cycle and provides the data to the vector lanes. The processing of those elements in the vector lanes will be overlapped in time with the supply of the next segment of the operand vector. This process, termed strip-mining, continues until the entire vector length is processed. Similarly, the generated output vector elements are written to the LVRF by the write DMA of ME. The MEEP VPU has 16 lanes of operations, and each pair of lanes is grouped and associated with a single ME, with a data width of 64 bytes. Thus, the MEEP VPU can receive data at a high bandwidth from the LVRF. In addition, the pairs of vector lanes can individually work on a thread of execution, thus opening the scope for multi-threaded execution (not yet supported).
Sparse vector operations are predominant operations in machine learning and many scientific applications. These operations do not benefit from the power-expensive cache memories due to an extremely small fraction of non-zeros in the operand sparse vectors. To address this issue, the Accelerated Compute and Memory Engines accelerator is specifically designed to support operations on sparse vectors in ACME-mode. The indexed reads or writes to vectors, which are the major latency-inducing steps in the sparse operations, are performed close to memory. These read vector elements are packed as a dense vector and then transferred to the LVRF. This scheme not only saves power by bypassing cache hierarchy but also reduces congestion in NoC by reducing the network traffic.