Continuous integration and Continuous Delivery (CICD) are standard practices in the SW world. It is hard to imagine a company that does not consider using this concept as part of the delivery flow. At the same time, there is no reason not to use CICD in the FPGA environment, where its use is usually less mature. In MEEP, we have prioritized a CICD system that robust the Field-programmable gate array (FPGA) development and the delivery process.
Usually, a CICD flow creates the final SW (binaries) starting from scratch: The process consists of cloning the sources in a clean space and then automating the necessary steps to build the final binary (or binaries). This automation is run by a set of scripts, a runner(s) that execute them, and a server that orchestrates the process in combination with the other two.
FPGA environment: scalability and reproducibility
In the FPGA environment, the sources are the RTL code and likely some script-level software that carries on the building of the FPGA system. In MEEP, we mainly use TCL to execute vendor-specific tasks (Xilinx/AMD), python, and bash scripting. This combination eases the scalability and reproducibility of the different projects: We can build the same project with a different set of parameters that yield a completely different system and always, of course, from scratch.
The CICD could stop after successfully synthesizing some RTL code, which would be fine. However, we are extending this approach to actual FPGA place and route, plus bitstream generation. We are targeting different FPGA boards (Alveo u280, Alveo u55c, Alveo u200, VCU128), programming them and running other benchmarks to validate and certify that the bitstreams are correct (or better than the previous one!).
From the project perspective, this whole ecosystem is not only one repository with all the pieces. This cross-project system involves RTL development, FPGA development, and SW development. This interconnection between different projects obliges to a set of policies that define the boundaries and which events trigger the other pipelines on the various repositories.
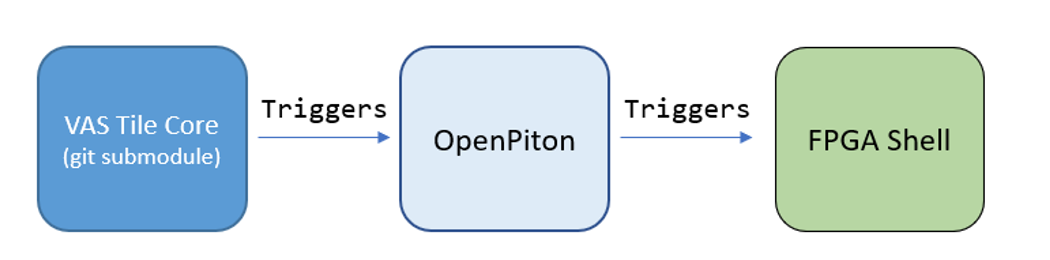
In MEEP, we are defining the following flow:
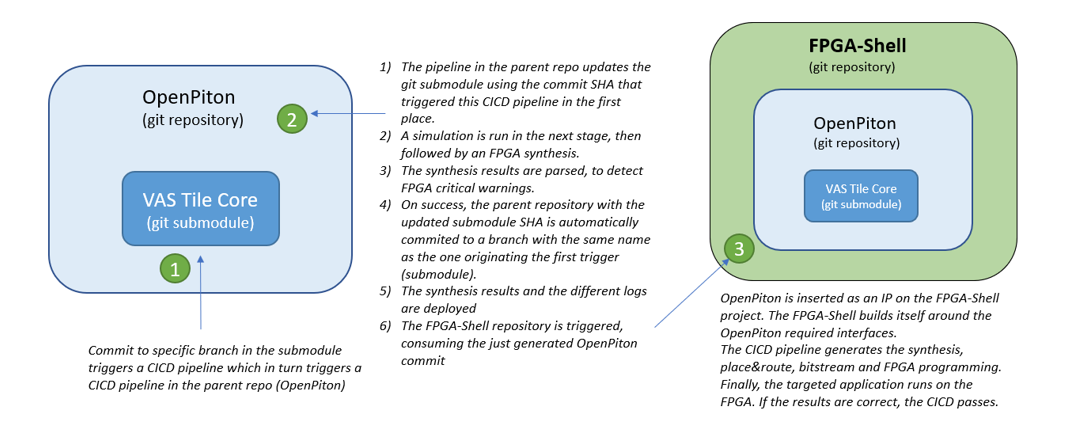
Core configurations, interfaces and features with OpenPiton
OpenPiton [reference] is a flexible project that allows many different core configurations, interfaces and features. For instance, OpenPiton allows selecting which Core is implemented in the system and how many of them are in the manycore architecture. The CPUs (fundamentally, RISCV architectures) are integrated into the OpenPiton filesystem as git submodules. The regular CICD flow orbits around repositories, so in a multi-project, multi-repository context, we need to implement a mechanism to communicate the different repository pipelines between them. This mechanism is the "trigger" feature. Some jobs in a channel can have as the only goal to be the triggering source of a downstream pipeline. As depicted in Figure 2, changes in the RISCV submodule, when committed to a specific branch, trigger the OpenPiton repository pipeline. OpenPiton is the parent in the sense it is the repo containing the submodule, thus, is the child from the triggering hierarchy point of view.
When triggered, the OpenPiton repository contains an outdated SHA for the submodule. One of the jobs in the pipeline is to update the submodule to be the one that triggered the channel. To achieve this, the submodule pipeline passes the SHA of the commit as a variable for the OpenPiton pipeline. This way, OpenPiton can update the submodule and do the necessary steps to complete the pipeline. As a last job, if the OpenPiton pipeline succeeds, the job commits the OpenPiton repository with the updated submodule, creating a new release version. This pipeline's main jobs are the RTL simulation and the FPGA synthesis, which verifies that the RTL is FPGA compliant. For instance, if the RTL is inferring latches or creating timing loops, a job in the pipeline detects them and makes them fail.

The process follows with a new trigger. This time, with the updated and successful OpenPiton repository, the trigger acts on the FPGA Shell project, which in turn gets the newly (and automatically) generated commit SHA for OpenPiton. OpenPiton, from the FPGA Shell perspective, is an IP that is dropped inside a set of interfaces, mainly PCIe and HBM. This new pipeline has a configuration of jobs that goes through the project creation to the bitstream generation. Typical FPGA flow steps include synthesis, place, and route. The synthesis, in this case, comprehends all the interfaces that the release configuration may need (Ethernet, Aurora, etc.), differentiating this synthesis from the synthesis carried on in the OpenPiton pipeline in the overall complexity. In the OpenPiton pipeline, there is no need to add any extra interface, as the main goal is to verify the RTL developed in the submodules and in OpenPiton itself.
The final jobs in the FPGA Shell pipeline are programming and testing the FPGA design. There is an expected output for the different configurations of the design. The other benchmarks are executed, and the result is read. If the read output matches the standard production, the pipeline passes. An example of this is booting Linux on the FPGA. If Linux boots, there are different messages during the booting that demonstrates that the FPGA design is successful. Lastly, the pipeline stores the various artefacts created on the other jobs on the runners' workstations. This is known as the deployment stage. This is useful for checking the main aspects of the design, getting the FPGA reports offline and comparing the details between different implementations. When this process happens on the FPGA Shell master branch, an extra job uploads the bitstreams to the MEEP official release site.
