As an evaluation platform of pre-silicon IP, MEEP needs tools to test new ideas at different stages of the development of a new hardware target. Different stages have different simulation requirements. Earlier ones require fast tools, which enable the comparison of disparate design points within reasonable time, even if that means lower fidelity. Early design tools also need to be easy to modify and extend, so getting a first-order comparison notion between two architectures does not involve excessive modelling effort. Only once the general flavor of the design has been decided using this kind of tools, low-level details start to become essential. This is when higher fidelity tools, such as FPGA-based emulation platforms, which require significantly more effort, come into play. In sum, the development of new architectures requires a multiscale approach: late design tools are impractical for design space exploration, while those for earlier stages lack the fidelity to capture low level details. This kind of multiscale approach is popular in the industry, as exemplified by the ARM Cycle Models and Fast Models [1].
Rich as it is, the RISC-V simulation ecosystem is still immature, and lacks some of the necessary tools to provide detailed information about the design-space exploration of HPC architectures. The available open source tools are not able to model the staple capabilities of HPC (high core counts [2,3,4 only non-open-source], complex memory hierarchies [5,6], vector architectures [7,8], etc.) or are too slow and hard to extend [9] to represent feasible options. For this reason, MEEP sets out to build a fast and flexible tool for the design-space exploration of HPC architectures.
Coyote
HPC architectures often feature high core counts and complex memory hierarchies. Therefore, when design space exploration is the goal, choosing the level of detail to capture in your simulation tools is the key. Too much level of detail and the simulation throughput will be poor, too few and comparisons will not be meaningful. Coyote[1] is a new open source, execution-driven simulation tool, based on the canonical RISC-V ISA, that has a focus on data movement throughout the memory hierarchy. This provides the right amount of detail to perform first-order comparisons between different design points, as the behavior of memory accesses and the well-known memory-wall are the main barrier to efficient computing.
___________
[1] MEEP is a reference to the roadrunner for its speed and efficiency. In the well-known cartoon, Wile E. Coyote aspires to match the roadrunner using his wits. This is precisely the goal of our simulator: matching the MEEP Hardware as closely as possible through approximations.
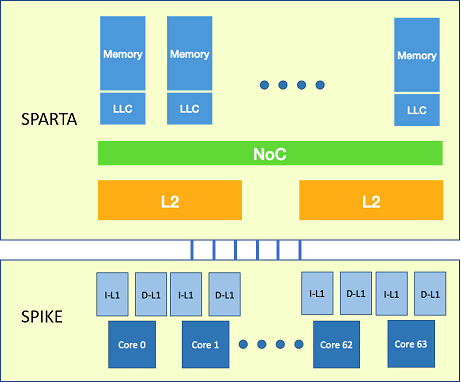
Figure 1 shows an example of an HPC architecture that could be reasonable to model as part of an exploration. Note that it neither represents the current capabilities of the tools, nor the actual MEEP Hardware design, but a sample system that could be considered for simulation. Three levels of cache and 64 cores are depicted. We consider these numbers big enough to draw significant conclusions and to reason about the even bigger architectures that the MEEP project targets, which would be unfeasible to simulate. Cache coherent systems might also be considered in the future, but the modelling of coherence protocols and traffic is currently beyond the scope of Coyote.
In order to develop a tool that is useful not just for MEEP, but to the whole RISC-V community, Coyote was not conceived as a completely new simulator, but as an integration of existing RISC-V tools. This is a desirable feature. It both leverages previous community efforts and also produces a tool that users find familiar and easy to adopt. Coyote is based on two pre-existing tools: Spike[5] and Sparta[10]. Spike, as the golden standard for RISC-V simulation, is a widespread tool within the community. It offers many of the required capabilities for HPC design space exploration, since it has a significant simulation throughput, supports vector instructions and the simulation of multicore systems. However, it lacks memory modelling features. To account for this, Sparta was used to build a flexible memory model capable of adapting to the changing needs of design space exploration. This model is based on a modular design, in which the functionality of each component (e.g. an L2 Bank) is encapsulated in an independent module. The result is a flexible and extensible model. Adding new functionality to a component is just a matter of modifying the corresponding module accordingly. Evaluating systems of different scales just requires varying the number of modules by connecting fewer or more depending on the case.
The purpose of Spike in this integration is providing its functional execution capabilities and also modelling the L1 caches. This decision is based on the idea of reducing the number of interactions between Spike and Sparta, in an attempt of improving the simulation throughput. Sparta is in charge of modelling the rest of the memory hierarchy, orchestrating the simulation and keeping track of timing. The pieces of the simulated system that are managed by each of the tools are shown in Figure 1. Every cycle, Sparta tries to simulate an instruction on each of the active cores using Spike. Spike runs in baremetal mode in order to leverage its capability to simulate multicore systems. An attempt to simulate an instruction has two possible effects:
- If a RAW dependency is detected on one of the operands of the instruction and a pending memory access, the core is marked as inactive. No further instructions will be simulated on this core until the dependency is satisfied.
- The simulation of an instruction might generate an L1 miss (or more). In this case, the information on the missing access(es) is communicated from Spike to Sparta. Sparta will generate the necessary events to target the modelled memory hierarchy accordingly. Once an L1 miss is serviced, the registers are set as available again, so any possible pending dependency is satisfied and stalled cores can resume their operation.
The memory modelling and simulation orchestration capabilities have been achieved using base Sparta classes. Spike has been minimally modified/customized to add the means to simulate instruction by instruction and track L1 misses and RAW dependencies. This only represented small additions and not a major rewrite of the whole simulator.
Coyote currently models a two level memory hierarchy. The instruction and data L1s are private to each core and modelled in Spike as stated before. The L2 is shared and modelled in Sparta. Its configuration can be set using input parameters, including its size, associativity and line size, the number of banks it is split into, the maximum number of in-flight misses, and the hit/miss latencies. Two different well-known data mapping policies have been implemented, that use different bits of the address to identify the L2 bank that holds a certain memory block: page-to-bank and set-interleaving. Simulation outputs statistics about memory accesses (miss rates, number of stalls due to dependencies, etc.), the execution time of the simulated application and a trace of the L1 misses. This trace can be analyzed using the paraver visualization tools \cite{paraver} to truly understand the behavior of applications, by identifying access patterns or analyzing how and when the L2 banks are stressed. Performance evaluation has been carried out simulating up to 128 cores, obtaining an aggregate simulation throughput of up to 5 MIPS, which enables design space exploration.
Four different kernels are adapted to baremetal simulation in Spike and are executed using Coyote. These kernels can be compiled using the standard GNU toolchain for RISC-V. These kernels are: a scalar matrix multiplication, a vector matrix multiplication, a vector SpMV (three different implementations of the algorithm) and a vector stencil. These are a basis to study the behavior of memory accesses under dense and sparse workloads. More kernels will be adapted in the future to cover the applications of interest to MEEP. These will include FFT, AI and other representative HPC and HPDA kernels.
Our work so far has set a solid foundation for a fast and flexible tool for HPC architecture design space exploration. It will enable designers to make informed decisions early in the development of new architectures, based on data movement, a key limiting factor of performance and efficiency. Next steps are to extend the capabilities of Coyote to model memory controllers, the NoC and different data management policies such as prefetching, streaming, etc. A study of the Sparta event scheduling scheme is also under way to adapt it to the needs of Coyote, with the intent of improving the simulation throughput.
References:
[1] The ARM Cycle Models and Fast Models, (October 2020) https://developer.arm.com/tools-and-software/simulation-models
[2] A. Rodrigues, K. S. Hemmertet al., “The structural Simulation Toolkit, ”SIGMETRICS Perform. Eval. Rev., vol. 38, no. 4, pp. 37–42, March 2011
[3] J. D. Leidel, “Stake: A Coupled Simulation Environment for RISC-V Memory Experiments,” in Proceedings of the International Symposium on Memory Systems. New York, NY, USA: Association for Computing Machinery, 2018, p. 365–376
[4] The riscvOVPsim Simulator, (October 2020) https://github.com/riscv/riscv-ovpsim
[5] The Spike RISC-V ISA Simulator, (October 2020) https://github.com/riscv/riscv-isa-sim
[6]The SAIL RISC-V Model, (October 2020) https://github.com/rems-project/sail-riscv
[7] F. Bellard, “QEMU, a Fast and Portable Dynamic Translator,” in Proceedings of the Annual Conference on USENIX Annual Technical Conference. USA: USENIX Association, 2005, p. 41
[8] The Renode Simulator, (October 2020) https://github.com/renode/renode
[9] N. Binkert, B. Beckmannet al., “The Gem5 Simulator,”SIGARCH Comput.Archit. News, vol. 39, no. 2, p. 1–7, Aug. 2011.
[10] The Sparta Framework. (October 2020) https://github.com/sparcians/map/tree/master/sparta