The MEEP project is emulating an accelerator (Accelerated Compute and Memory Engine - ACME) that in 5 years will be committed to a chiplet. In the first approach to this accelerator, the project is focused on the development of its main components, starting from the Computation Engine. This component is composed of a grid of multiple instances of a VAS Tile, which are interconnected by a network-on-chip.
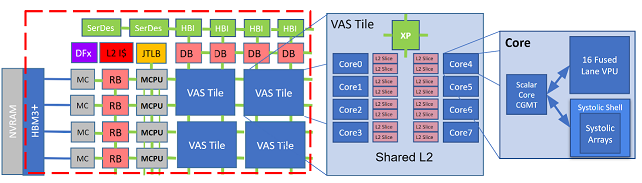
The VAS Tile is a cluster of 8 scalar cores, with each core supporting several coprocessors; a Vector Processor Unit (VPU) and two Systolic Array Units. Each scalar core has its own L1 instruction and data caches, a L2 data cache slice which also can act as a scratchpad to provide direct access to the coprocessors, as an extension of their vector register banks.
A VAS Tile core in ACME
Each VAS Tile is connected to a Memory Tile, and the scalar cores are in charge of orchestrating the disaggregated workflow between that Memory Tile and its own coprocessors to keep the execution flow synchronized.
After evaluating several RISC-V IP cores, the chosen candidate to play the role of a scalar core in the VAS Tile is Lagarto Hun, a RV64IMA core with a 5 stage pipeline in order, supporting privileged ISA v1.11 [DRAC]. There exist several reasons why this processor was chosen. First, this processor includes an interface with a vector processing unit; and it is an in-house RISC-V processor well-known by the Barcelona Supercomputing Center (BSC). Second, by using Lagarto, MEEP can contribute to the evolution of this processor. The core also includes, apart from the VPU [EPI], the possibility of having two systolic array (SAs) co-processors.
One of the goals of MEEP project, as part of the ACME accelerator, is to enhance the EPI VPU by partitioning the vector register file to support lane pairs for multithreading executions, reducing its number of elements up to 32 elements (in HPCG, for SpMV Kernel the average vector length is 25), analyze a new inter-lane communication, and add a direct memory interface to the data L2 cache when it is used as scratchpad.Thus, the vector register file can be extended virtually for supporting long vectors through micro-engines (DMA engines).
Each VAS Tile core will include the capability of supporting two systolic arrays co-processors. One targeting video & image processing (SA-HEVC) and the other targeting neural network acceleration (SA-NN). Like the VPU, the SAs require some management, as well as access to memory; which are provided through the same interfaces as the VPU. The scalar core provides the control and orchestration of the SA, and the L2 scratchpad provides the streaming memory interface to the SA to enable sustained high performance.
A VAS Tile in ACME: A multi-core system
The MEEP project takes advantage of a well-known open-source project, called OpenPiton, because of its configurable, and scalable multi-core system nature, as the first approach to a VAS Tile in ACME.
OpenPiton Project
OpenPiton [OpenPiton] is a general-purpose, multi-threaded, many-core processor and framework designed by the Princeton Parallel Computing Group [PPCG]. OpenPiton is open source across the entire computing stack, from the hardware to the firmware and software. OpenPiton is designed to be highly configurable, including core count, cache sizes, and NoC topology, enabling it to adapt to different use cases, which is the reason why OpenPiton was chosen for the first approach to a many-core system.
OpenPiton is a tiled-manycore architecture, as shown in Figure 2. It can be both, scalable intra-chip and inter-chip.
Intra-chip: The tiles are connected via three networks-on-chip (NoC) in a 2D mesh topology. The scalable tiled architecture and mesh topology allows for the number of tiles within an OpenPiton chip to be configurable. By default, the NoC router address space supports scaling up to 256 tiles in each dimension doing a total of 64K cores/chip.
Inter-chip: An off-chip interface, known as the chip bridge, connects the tile array to off-chip logic (chipset), which may be implemented on an FPGA or ASIC. The bridge extends the three NoCs off-chip, multiplexing them over a single link. This allows the creation of a larger system as shown in Figure 2. The cache-coherence protocol can be extended off-chip as well, enabling shared memory across multiple chips.
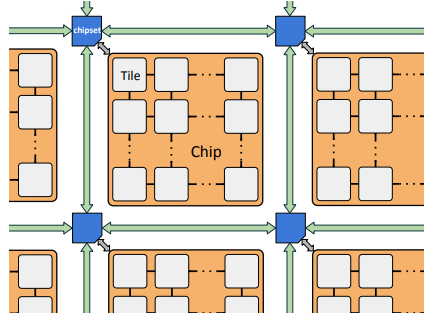
Taking into account all of this, OpenPiton can provide MEEP a basic infrastructure to probe, test, and tune the ideas related to the ACME VAS Tile.
Reference design
Originally, OpenPiton adopted the OpenSPARC T1 core but then other processors such as the PICORV32, a RISC-V processor of 32 bits, and Ariane RV64GC, a RISC-V processor of 64 bits have been supported.
In order to support Ariane, some changes were needed to adapt the memory hierarchy of the system to Ariane's one. This was due to the fact that Ariane is equipped with a different L1 cache subsystem that follows a write-through protocol and that has support for cache invalidation and atomics. Consequently, an intermediate layer was designed to adapt this L1 cache to the L2 in OpenPiton. As a result, this L1 cache system is directly connected to the L1.5 cache provided by OpenPiton’s P-Mesh, like it is shown in Figure 3.
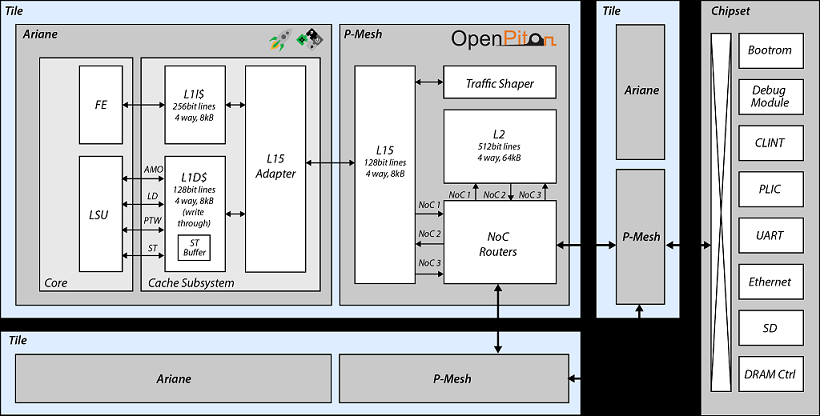
Before starting any modification in the shape of moving closer to the ACME VAS Tile, OpenPiton with Ariane RV64GC was an initial reference design. First, this speeds up the ramp-up to understand the structure of the system, to understand the data and instruction flow, and get familiar with the different pieces that conform to the project. In addition, Ariane RV64GC is a 64bits RISC-V processor, which allows the reuse of all the available RISC-V tests and Benchmarks already supported in OpenPiton with Ariane by Lagarto Hun. At the same time, this framework offers a simulation space for comparison among both cores.
Integrating MEEP core in OpenPiton
The replacement of one core for another (Ariane for Lagarto Hun) is not immediate and requires an integration process. As part of it, it can be re-used components on OpenPiton that have been developed for Ariane to support Lagarto, such as the BootROM, peripherals, CSR, and Cache subsystem.
The approach used to integrate MEEP core into OpenPiton is the same as the Ariane. That means, using an adapter to connect the L1 cache system to the P-Mesh in OpenPiton. In order to save time and reduce complexity, the integration of Lagarto Hun reuses the same Ariane’s L1 Cache Subsystem. The overview of the final design is depicted in Figure 4.
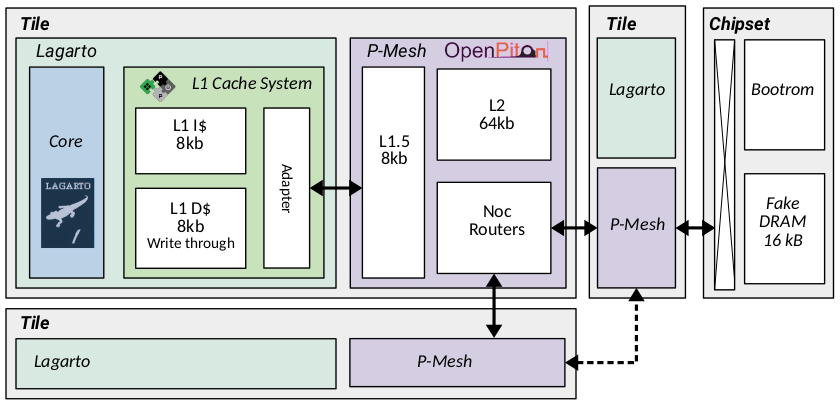
A Tile in OpenPiton needs to be adapted to be able to instantiate a Lagarto core. This means doing modifications by a Systemverilog “generate” keyword in OpenPiton scripts, to pass the option of enabling Lagarto as the processor in the tile as a parameter.
As the first approach, MEEP’s core will be composed of Lagarto plus the Ariane cache subsystem, which is connected to the L1.5 cache. The front-end of Lagarto will be connected to the Instruction Cache through an instruction cache interface which will have the logic to translate requests and responses from Lagarto to the Instruction Cache. Moreover, Lagarto is connected to the Data Cache through the data cache interface which will traduce the request and response from Lagarto to the Ariane Cache Subsystem.
Current status
Currently, this L1 cache system has been successfully connected to Lagarto Hun. Actually, the Instruction Cache and the Data Cache are able to pass the initial RISC-V ISA Tests as the rv64ui-p-add, rv64ui-p-sd, and rv64ui-p-ld.
Another feature that has been included is the capability to generate signatures from Lagarto. Scripts had been added to run the ISA Tests over OpenPiton and Spike comparing both signature and spoken differences between both simulations. This is a powerful tool to debug the integration of Lagarto into OpenPiton.
CSRs are partially connected, progressing at the same time as the execution of the ISA tests.
Atomic cache interface in the data cache is another task that we are working on to allow Atomic Memory Operations.
Once the integration is completed, it is expected that all the ISA Tests and Benchmark supported by Lagarto run successfully. From this point on, the system will be moved to real hardware to start doing some measurements and benchmark over the Alveo U280 platform. Ideally, we should be able to boot Linux 5.8 which is actually supported by Lagarto Hun. Furthermore, the MEEP core will be completed by integrating several coprocessors as part of it; more explicitly, the VPU and the SAs.
References
[OVI] Open Vector Interface (September 2020), https://github.com/semidynamics/OpenVectorInterface
DVINO, the second generation of the Lagarto processor series, submitted for fabrication via Europractice (May 2021), https://drac.bsc.es/en/media/news/tech-dvino-second-generation-lagarto-processor-series-submitted-fabrication-europractice
MEEP. MareNostrum Experimental Exascale Platform https://meep-project.eu
J. Abella et al., "An Academic RISC-V Silicon Implementation Based on Open-Source Components," 2020 XXXV Conference on Design of Circuits and Integrated Systems (DCIS), 2020, pp. 1-6, doi: 10.1109/DCIS51330.2020.9268664.
[DRAC] https://drac.bsc.es
[OpenPiton] https://github.com/PrincetonUniversity/openpiton
[PPCG] Princeton Parallel Computing Group: http://parallel.princeton.edu
OpenPiton Paper - ASPLOS '16 Conference Paper. http://parallel.princeton.edu/papers/openpiton-asplos16.pdf
OpenPiton Microarchitecture Specification. http://parallel.princeton.edu/openpiton/docs/micro_arch.pdf
Piton Paper - IEEE Micro, March/April 2017 http://www.parallel.princeton.edu/papers/piton-micro-mag-17.pdf
F. Zaruba and L. Benini, "The Cost of Application-Class Processing: Energy and Performance Analysis of a Linux-Ready 1.7-GHz 64-Bit RISC-V Core in 22-nm FDSOI Technology," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 27, no. 11, pp. 2629-2640, Nov. 2019, doi: 10.1109/TVLSI.2019.2926114.