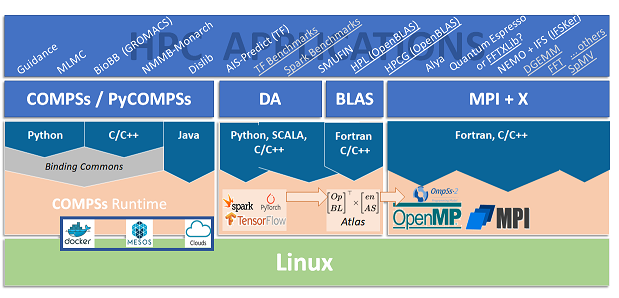
We have identified a suite of potential workloads to accelerate on the MEEP platform:
- Emerging bioinformatics applications.
- Emerging HPDA (High-Performance Data Analytics) frameworks.
- Traditional HPC applications.
As shown from left to right in the figure below, there is a rich set of applications and we will focus on the applications that simultaneously have the most RISC-V ecosystem support and the largest HPC impact.
Emerging bioinformatics applications
MEEP will consider in its applications portfolio some of applications and application workflows from different application areas that are developed on top of PyCOMPSs/COMPSs (see the Software Toolchain tab). Some of these are:
- Multi-Level Monte Carlo (MLMC) codes.
- BioBB library (including GROMACS).
- Multiscale Online Nonhydrostatic Atmosphere Chemistry model (NMMB-Monarch).
- Dislib ML library, or the SMUFIN code.
Emerging HPDA frameworks and applications
For HPDA, the idea is to mainly use benchmarks (such as the TensorFlow's Official Models and the Spark-Bench), and possibly internal workloads like the AIS-Predict, a TensorFlow application for vessel trajectory prediction. Likewise, we will use Bolt65 suite, a just-in-time video processing software in the HPDA collection.
MEEP will use microkernels (such as DGEMM, SpMV, FFT, and others), representative code hot spots (functions, loops, etc.) to drive the software/hardware co-design aspects of the MEEP accelerator. Our focus in that case is set on the performance-efficiency achieved by low-level optimizations for the efficient exploitation of the architecture.
MPI+X workloads
- HPC benchmarks such as HPL (High Performance Linpack).
- HPCG (High Performance Conjugate Gradient) and continuing with four widely used HPC applications: Quantum Espresso, Alya, NEMO, and OpenIFS.