The MEEP project provides generic programming environments for emulated hardware running on MEEP. Today, there are two popular program execution modes. MEEP will support the two different program execution approaches:
- The self-hosted mode will behave like a multiprocessor environment (with many processing elements) where all the software components run on the system in a native mode.
- The offload mode is based on a host-device interaction, in which the dense computational part of the application is offloaded to the device (also called accelerator).
The following figure shows a comparison of these two modes.
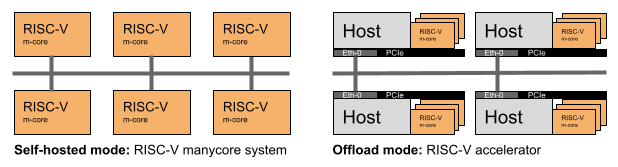
Programming these two architectures are two different processes.
In the self-hosted mode, the parallelism will be expressed in terms of a combination of a distributed programming model (MPI) and a shared-memory programming model (OpenMP); both running in the RISC-V architecture. While in the offload mode both, MPI and OpenMP will run on the host architecture (e.g., x86), but the host is also able to offload heavy computational parts (i.e., application’s kernels) of the code to the accelerator device. We can manage the kernel offloading by means of the target constructs of the OpenMP programming model. Programmers must also consider different memory address spaces and data movements between them. OpenMP also provides mechanisms to ease these operations (e.g., the map clause of the target construct).
The MEEP Prototype
The MEEP project consists of a set of hardware IPs and software components, all running on FPGAs that emulate the system. An FPGA is a programmable hardware device. Combined, the hardware IP and software components form the MEEP prototype, or Emulated Accelerator, ACME, mapped to an FPGA device. The Emulated Accelerator can be anything that can be mapped to the FPGAs. ACME (Accelerated Compute and Memory Engine) is a self-hosted accelerator targeting legacy and emerging HPC applications with both dense and sparse workloads.
The main benefit of the prototype is that it looks similar to the previously presented offload mode, but users should consider that the prototype could actually implement both execution modes.
The following figure shows the relationship between MEEP prototypes and the actual system.
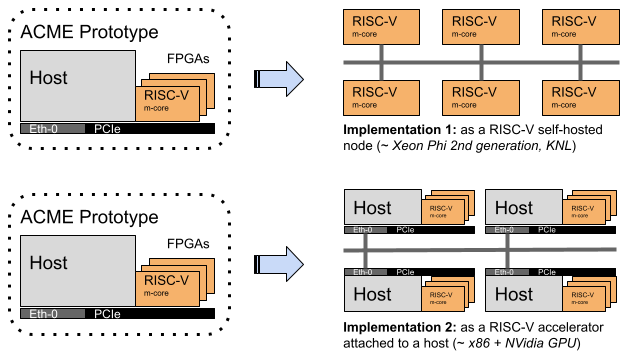
When interacting with the prototype, it may be considered, if the host system:
- Is actually active from the point of view of computational load; i.e., the host executes parts of the program.
- Is just a bypass element (helping to carry out certain functionalities not included in the FPGA device).
Operating System support
The main objectives of the Operating System layer are:
1. Allowing the Linux OS to boot on the ACME Emulated Accelerator platform;
2. Proposing an ACME recommended Linux distribution fulfilling the needs of the higher-level layers in the software stack;
3. Implementing a set of system’s services and extensions that will allow the communication host-to-fpga and fpga-to-fpga.
Booting a Linux kernel (objective 1) involves multiple software components that take part in bringing up the system. These are:
⦁ The Bootrom (including the Device Tree Blob, DTB): The ACME Emulated Accelerator platform will already provide an embedded bootrom.
⦁ The Hypervisor: Standard OpenSBI will be used (with minor adjustments, to adapt them to the architecture).
⦁ The Bootloader: Standard U-Boot will be used (with minor adjustments, to adapt them to the architecture).
⦁ The Linux Kernel: A minimal Linux distribution (objective 2) will be used (i.e., disabling unnecessary kernel features and tuning key Linux parameters for our system) initially based on Fedora 33. That minimal distribution becomes the starting point of the rest of libraries and runtimes that should be enabled for the project.
⦁ The User Services: Also based on Fedora 33. Early ACME Emulated Accelerator releases may require Buildroot support.
With respect to the system’s services and extensions (objective 3), the Operating System will provide support on two different communication’s scenarios:
⦁ Host/FPGA communication: The plan is to adapt the Virtio Over PCIe (VOP) and the Symmetric Communication Interface (SCIF). Both of them are the two major components of Intel’s Xeon Phi Software stack that enable networking between a host and PCIe cards. VOP offers a transparent communication layer from the user-perspective, at the expense of efficiency SCIF is a Linux Kernel API that enables faster communications over PCIe than VOP, but requires explicit use of their API on user applications or runtimes.
⦁ FPGA/FPGA communication: Developing a Linux Ethernet driver for the Ethernet IP block in the SoC design on top of the QSFP+ connections provided by the Alveo U280 FPGAs.
Among these two presented scenarios, the Operating System also includes the early communication support, based on the tun-on-mmap approach: this is, leveraging a special memory mapped region shared between the host and the device, and a network tunnel reading/writing on it.
The tun-on-mmap is a first feasible option to demonstrate that networking works. It allows the platform’s users to test several Fedora packages that are dependent on networking, like the secure socket layer and related tools, and also the Fedora package manager (i.e., dnf).
Compiler support
Compiler support work spans many different areas:
The first area covers the architecture support, identifying new instructions as important additions to the RISC-V architecture (vector and systolic array extensions), which will be accessible via an instruction interface.
Another area covers the programming model support. As the MEEP infrastructure can present multiple devices, this poses a challenge to OpenMP, whose device model is oblivious of a reality where work could be offloaded to multiple devices at the same time.
Finally, there is an area that covers optimisations of the vector-length agnostic scenario enabled by the RISC-V architecture.
The compilation infrastructure is based on the LLVM compiler, which provides the optimization and code generation capabilities for different architectures, including RISC-V. C/C++ support is provided by the clang front end.
As defined in the introduction, the MEEP project has defined two different execution modes:
⦁ Self-hosted
⦁ Offloading.
The compiler should be able to generate the following binaries:
⦁ A fat binary, containing host (e.g., x86) and ACME Emulated Accelerator code (i.e, RISC-V); for the offload mode;
⦁ A pure RISC-V binary that will execute directly in the ACME Emulated Accelerator; for the self-hosted mode.
The following figure shows the compiler toolchain for both cases:
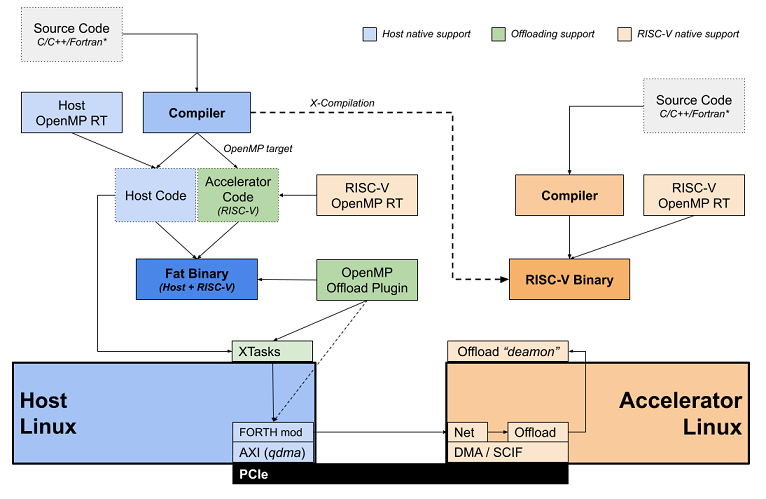
For the fat binary executable, the mechanism to distinguish which part of the code must be offloaded to the accelerator is the OpenMP target directive, and data transfers will be controlled by means of the OpenMP mapping clauses. The compiler will split the source code in different object files: the host code which will be linked with the Host OpenMP Runtime; the accelerator code which will be linked with the RISC-V OpenMP Runtime.
When using the offload execution model, there are several devices that can be used to offload computation. The MEEP project is extending OpenMP language, so it can offload regions of code to more than one device at a time. The extension is based in a new OpenMP construct, called target spread:
int N = ...;
int A[N], B[N], C[N];
init(A, B, N);
#pragma omp target spread \
nowait \
devices (2,0,1) \
spread_schedule(static , 4) \
map(to: A[omp_spread_start :omp_spread_size ]) \
map(to: B[omp_spread_start - 1: omp_spread_size + 2]) \
map(from: C[omp_spread_start:omp_spread_size ])
for (int i = 1; i < N - 1; i++) {
C[i] = A[i] + B[i - 1] + B[i] + B[i + 1];
}
The target spread construct allows users to distribute the loop iteration space over a number of devices. Each device is assigned a number of chunks following a given schedule. These chunks once distributed can be used to determine the data mapping between the host and the target using special variables that designate the start and size of the chunk.
For the RISC-V binary executable, the compiler only requires to build the whole program just targeting the RISC-V architecture, and the resulting binary must be linked with the RISC-V OpenMP Runtime.